QUOTE(Peter Damian @ Sat 29th October 2011, 5:12am)

QUOTE(Tarc @ Sat 29th October 2011, 3:27am)
Is that necessarily a bad thing, though? Take any topic, let's say the Beatles. Editors have gone there over the years, created articles on the band, albums, tours, controversies, places, and influences. A Beatles fan comes along post-2008, and finds most everything he can think of to be covered already. Same with others, from WWII to Lost to Lady Gaga, perhaps there is a saturation point where there just isn't much new content to generate, therefore less editor participation.
Of course there are current events to write about, from the legitimate (Libyan revolution) to the asinine (anything the ARSEholes promote...listeria outbreaks, crazy guys who let exotic animals loose, Rebecca Black clones, etc...) but that has always been the case.
Ah yes, this is the 'already contains the sum of human knowledge' argument.
http://ocham.blogspot.com/2011/10/crowdsou...philosophy.htmlQUOTE(Kelly Martin @ Sat 29th October 2011, 5:04am)
So there is a huge article space that Wikipedia is lacking in, and can never fill, because it's structurally incapable of doing so. It's also what keeps Wikipedia from credibly claiming to be an encyclopedia.
Why aren't Wikipedians persuaded of this?
Well, this is just going to echo what some other people are saying/have said, but basically think of the word "encyclopedia" as a brand name. The hard way to establish a brand name - essentially "reputation capital" - is by providing a quality product consistently over a long period of time. But this takes lots of effort, organization, and basically... real work. So the easy way is to appropriate a brand name, in this particular case the word "encyclopedia". Then you get at least some of the benefits of the reputation (some, because not everyone is fooled), with much much much less real work.
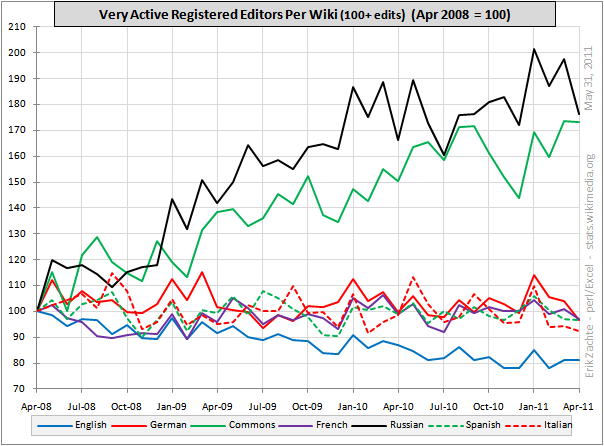
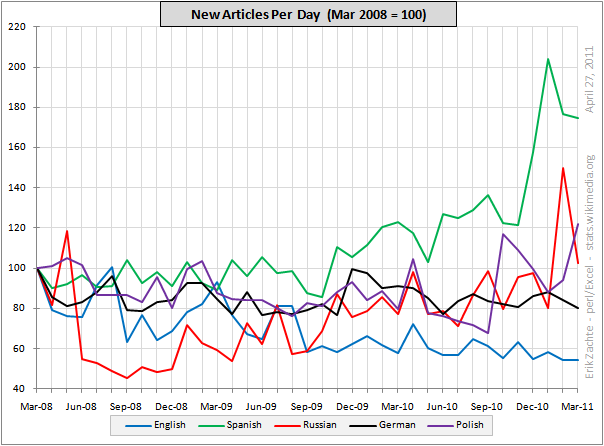
And as long as you can maintain the veneer that the brand name is appropriate it can work. For awhile. Then the realization starts seeping in that the brand name might not be so reputable anymore. So you try and stave that off by publishing misleading and irrelevant (though, I think, essentially true) statistics about the number of articles in your "encyclopedia". You "cook the books" by including low quality (analogy: crappy, high risk "toxic assets") one or two sentence stubs along with whatever legitimate assets you actually posses. It looks good on paper and, at least temporarily you fool some people into accepting that you are what your brand name says. But long term, this kind of practice (in this case, substituting lots of low quality stubs and similar junk for real articles on topics, as Kelly says) is not sustainable. So yeah, that's why it's dying.
So why are Wikipedians putting up with this? Well, first, a lot of them are not - and they're expressing their dissatisfaction with basically the only real way that Wikipedia structures allow; by leaving the project. Which we see in the data above.
Why do the others remain? A few reasons.
First some people have an emotional stake in a particular sub topic. So their thinking is "yeah, this place sucks, but maybe I can at least make some small corner of it not suck. Let me tend to my own garden". Problem is that they are vastly outnumbered by all the crazies, psychopaths and power mongers. This has basically been my own justification of still doing something over there. But yeah, I'm coming more and more to realize how futile this is.
Aside from that, the smart but cynical ones realize it's all a sham but hope that the illusion can be sustained for a while longer. Or they they realize that they're probably not going to be part of the "project" for much longer. The average tenure of a Wikipedian is pretty low. So if your horizon is like one or two years, then who cares if eventually everyone realizes the whole thing is a joke, as long as for the immediate future you get to strut your stuff around. These people have a stake in actively promoting the illusion that the project is doing just fine so they LIKE all the goofy stubs, the inflated edit counts, and the SPAM that is more or less taking over in terms of article creation. (So I checked, apparently Dr. Blofeld is apparently not a bot. He is, however, still basically a spammer)
The other group is composed of those that, as we say around here, "have drunk the kool aid". But every year this group gets smaller and smaller. The typical profile of such an editor, from what I seen, is something like:
1. Get on Wikipedia. Talk a lot about how awesome it is.
2. Viciously attack anyone who disagrees that Wikipedia is awesome.
3. Retire after a year never to be heard from again.
Most of these are young kids who are just into current "one hit wonder band" but whose enthusiasm burns out pretty quickly. And as the illusion that "the project" is doing good gets harder and harder to sustain, there is less and less of these.
Finally there are some who basically devoted their lives to the project, for better or worse. I'm perfectly willing to entertain the notion that their original intentions were noble. They meant well, but not having had any kind of experience with this kind of thing, the whole thing became a Frankenstein monster governed and motivated by its own idiocies and whims. BUT, these folks have invested so much into the project that there's no way in the world that they're going to admit that it sucks, because that would mean that they wasted the last... five? six? years of their lives on a dead end.
In economics this is called the "Sunk cost fallacy". If you invest a lot upfront into what turns out to be a bad investment project which ends up causing continued negative profits, then the rational thing to do is to write off the upfront investment and look for better alternatives. It is NOT to continue pouring money into the bad investment on the slim chance that things will turn around or the irrational belief that things aren't as bad as they seem. Of course, in the real world people are not rational so they commit the "sunk cost fallacy" all the time - because they become emotionally attached to something that is a failure just because it is THEIR failure. Same thing here. Some of the "old guard" persist exactly for this reason.
Anyway, just trying to un-hijack the thread here.