The Reg : Google and the Great Wikipedia Feedback Loop
http://www.theregister.co.uk/2009/01/26/br...a_slaps_google/
Google's Wikidependence is worse than ever. And Jorge Cauz thinks it's time for an intervention.
"If I were to be the CEO of Google or the founders of Google, I would be very [displeased] that the best search engine in the world continues to provide as a first link, Wikipedia," the Encyclopedia Brittanica president told The Sydney Morning Herald last week during a visit Down Under. "Is this the best they can do? Is this the best that [their] algorithm can do?"
Full Version: Cade Metz on Wikipedia and Google
QUOTE(Kato @ Mon 26th January 2009, 10:17pm) 
The Reg : Google and the Great Wikipedia Feedback Loop
http://www.theregister.co.uk/2009/01/26/br...a_slaps_google/
Google's Wikidependence is worse than ever. And Jorge Cauz thinks it's time for an intervention.
"If I were to be the CEO of Google or the founders of Google, I would be very [displeased] that the best search engine in the world continues to provide as a first link, Wikipedia," the Encyclopedia Brittanica president told The Sydney Morning Herald last week during a visit Down Under. "Is this the best they can do? Is this the best that [their] algorithm can do?"
I'd like to hear a Google spokesman either confirm or deny that they purposefully promote Wikipedia.
When it's somebody at Britannica complaining about Wikipedia's Google position, it ends up sounding like sour grapes about his own product not faring as well.
QUOTE(Cla68 @ Mon 26th January 2009, 11:11pm)
I'd like to hear a Google spokesman either confirm or deny that they purposefully promote Wikipedia.
That's extraordinarily unlikely to happen - Google likes to keep its sauce secret.
But it's pretty clear that wikipedia gets a free pass on the Google result page, even where it adds no content. Look at the speed new stubs can make it to #1, with zero inbound links, and alternative results to choose from.
Created about three-and-a-half hours ago, by copying information from a single web page -
- and the web page that got lifted from is relegated to position five:
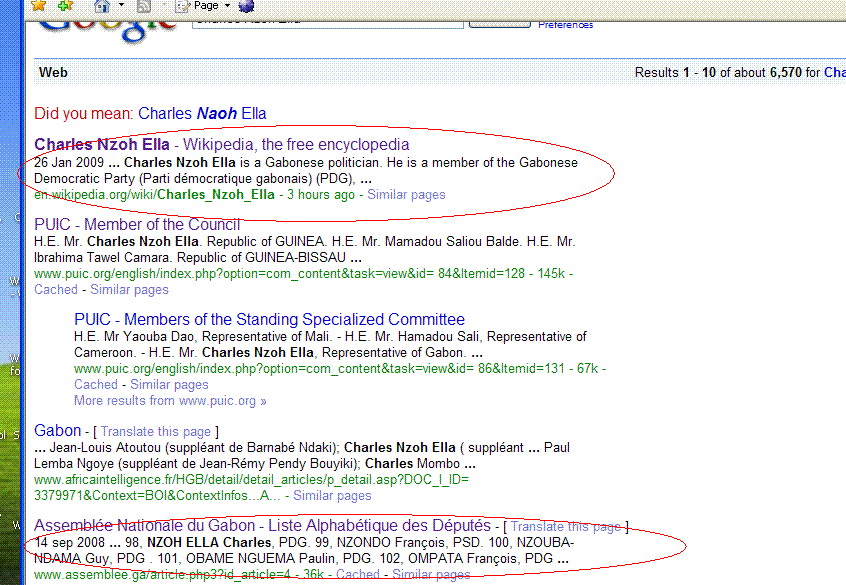
Quite how wikipedia adds to "the sum of human knowledge" here is beyond me - but Google's bias towards crappy pages like this is the only real reason wikipedia gets so many hits.
QUOTE(UseOnceAndDestroy @ Tue 27th January 2009, 12:46am)
QUOTE(Cla68 @ Mon 26th January 2009, 11:11pm)
I'd like to hear a Google spokesman either confirm or deny that they purposefully promote Wikipedia.
That's extraordinarily unlikely to happen - Google likes to keep its sauce secret.
But it's pretty clear that wikipedia gets a free pass on the Google result page, even where it adds no content. Look at the speed new stubs can make it to #1, with zero inbound links, and alternative results to choose from.
Created about three-and-a-half hours ago, by copying information from a single web page -
- and the web page that got lifted from is relegated to position five:
Quite how wikipedia adds to "the sum of human knowledge" here is beyond me - but Google's bias towards crappy pages like this is the only real reason wikipedia gets so many hits.
I believe the reason I became interested in Wikipedia was because I kept seeing it at the top of Google searches I was doing several years ago. I wonder where Wikipedia would be now without Google's help?
Perhaps this is my blonde, but I thought the Google guys and Jimbo were bitter enemies.
QUOTE(LaraLove @ Mon 26th January 2009, 9:52pm)
Perhaps this is my blonde, but I thought the Google guys and Jimbo were bitter enemies.
Larry Page and Sergei Brin are Stanford grads.
One of the things you learn at Stanford is Ethics.
Google may be in competition with Wikipedia in some ways (e.g. Knol), but Google is an outstanding example of a Learning Organization in pursuit of Best Ethical Practices.
Google's Motto ("Don't Be Evil") is a reflection of its pursuit of Best Ethical Practices.
QUOTE(Moulton @ Tue 27th January 2009, 3:28am)
One of the things you learn at Stanford is Ethics.
Google may be in competition with Wikipedia in some ways (e.g. Knol), but Google is an outstanding example of a Learning Organization in pursuit of Best Ethical Practices.
Google's Motto ("Don't Be Evil") is a reflection of its pursuit of Best Ethical Practices.
And here's Larry Page at Stanford, taking his final exam for the graduate course in "Computers and Social Ethics":

Moulton, you quoted me like you were responding to me, but you didn't say jack in reference to my question. I swear, I click to view your posts maybe once out of every dozen... and it's always a mistake.
QUOTE(LaraLove @ Tue 27th January 2009, 12:28am)
Moulton, you quoted me like you were responding to me, but you didn't say jack in reference to my question. I swear, I click to view your posts maybe once out of every dozen... and it's always a mistake.
Ethics inform us how to treat our adversaries.
You used the term "bitter enemies" but I reckon that Google views Wikipedia as a competitor, not a "bitter enemy".
One of the things one learns when reckoning the ethical considerations in dealing with one's adversaries is how to go about it in a way that doesn't escalate the enmity or the bitterness.
When I worked for the Bell System, we had competitors who were also our customers and also our suppliers. We learned that it was unethical to treat our competitors in ways that political enemies are wont to treat each other.
It's like playing chess. You treat your adversary fairly. You don't make up rules that benefit your pieces or disadvantage your opponent's pieces.
That's what's wrong with Wikipedia (and what's right with Google).
Larry Page and Sergei Brin have a decent sense of business ethics.
Jimbo, alas, does not.
I reckon that's one reason he and Larry Sanger went their separate ways.
You may be interested in the talk page at Wikipedia Review here
http://wikipediareview.com/User_talk:Wikipedia Review
In summary. My version of the article 'On Interpretation'
http://wikipediareview.com/On_Interpretation
is longer and more complete than the one on Wikipedia
http://en.wikipedia.org/wiki/De_Interpretatione
So I experimented to see what would happen if I added a phrase from the MWB version to the Wikipedia one, as follows
http://en.wikipedia.org/w/index.php?title=...oldid=257325112
Before this addition, the following search
http://www.google.co.uk/search?hl=en&q=%22...enials%22&meta=
only referenced the MWB (because of the added phrase only being in MWB). However, as soon as the Google spider picked up the addition, it instantly shows the Wikipedia one
De Interpretatione - Wikipedia, the free encyclopediaAristotle enumerates the affirmations and denials that can be assigned when ' indefinite' terms such as 'unjust' are included. He makes a distinction that ...
en.wikipedia.org/wiki/De_Interpretatione - 26k - Cached - Similar pages
In order to show you the most relevant results, we have omitted some entries very similar to the 1 already displayed.
If you like, you can repeat the search with the omitted results included.
and worse, it hides the MWB version like it was some scraper version of the original article. Awbrey's explanation on the talk page is that Google works by a networking algorithm.
[edit] However if you Google a phrase which is still not in the Wikipedia version, you still get the MWB version
http://www.google.co.uk/search?hl=en&q=%22...posite%22&meta=
http://wikipediareview.com/User_talk:Wikipedia Review
In summary. My version of the article 'On Interpretation'
http://wikipediareview.com/On_Interpretation
is longer and more complete than the one on Wikipedia
http://en.wikipedia.org/wiki/De_Interpretatione
So I experimented to see what would happen if I added a phrase from the MWB version to the Wikipedia one, as follows
http://en.wikipedia.org/w/index.php?title=...oldid=257325112
Before this addition, the following search
http://www.google.co.uk/search?hl=en&q=%22...enials%22&meta=
only referenced the MWB (because of the added phrase only being in MWB). However, as soon as the Google spider picked up the addition, it instantly shows the Wikipedia one
QUOTE
De Interpretatione - Wikipedia, the free encyclopediaAristotle enumerates the affirmations and denials that can be assigned when ' indefinite' terms such as 'unjust' are included. He makes a distinction that ...
en.wikipedia.org/wiki/De_Interpretatione - 26k - Cached - Similar pages
In order to show you the most relevant results, we have omitted some entries very similar to the 1 already displayed.
If you like, you can repeat the search with the omitted results included.
and worse, it hides the MWB version like it was some scraper version of the original article. Awbrey's explanation on the talk page is that Google works by a networking algorithm.
[edit] However if you Google a phrase which is still not in the Wikipedia version, you still get the MWB version
http://www.google.co.uk/search?hl=en&q=%22...posite%22&meta=
Vide —
Sergey Brin and Lawrence Page : The Anatomy of a Large-Scale Hypertextual Web Search Engine
Weenie, Widdie, Wiki …
Ja³
Sergey Brin and Lawrence Page : The Anatomy of a Large-Scale Hypertextual Web Search Engine
Weenie, Widdie, Wiki …
Ja³
Google clearly gives a lot of juice to Wikipedia. My blog gets absurdly high search positioning for as irrelevant as it is. Part of this might because I'm an AdSense partner, and because I publish on Blogger, but I think it's also aided because Google has me tagged as a Wikipedia-sphere content producer, driving my juice up.
I almost never blog about Wikipedia anymore, but I still get the juice. Google's weird.
I almost never blog about Wikipedia anymore, but I still get the juice. Google's weird.
QUOTE(Jon Awbrey @ Tue 27th January 2009, 7:58am)
Vide —
Sergey Brin and Lawrence Page : The Anatomy of a Large-Scale Hypertextual Web Search Engine
Weenie, Widdie, Wiki …
Ja³
This is great Jon.
QUOTE
Running a web crawler is a challenging task. There are tricky performance and reliability issues and even more importantly, there are social issues.
---Brin & Page
---Brin & Page
...and with this B&P never look back or revisit those challenging social issues. No further discussion in the paper. No references dealing with the matter. Not even a nod to "this is beyond the scope of this paper." Just silence.
Eventually these challenging social issues would require a really catchy cliche, Don't be Evil ™.
By the way, Jon, can you break down the architecture stuff a little. I couldn't really follow it.
 "A major research interest is data mining..." —Sergey Brin, 1999
"A major research interest is data mining..." —Sergey Brin, 1999 __________________________________________________
From the résumé of Matt Cutts, the most prominent Google engineer since he was hired in 2000:
QUOTE
January 1992 - August 1994
Department of Defense, 9800 Savage Road, Ft. George G. Meade, MD 20755-6000
Co-operative education student
Completed four work tours (over a year total) with the National Security Agency. During my first tour I produced a sizable report on UNIX security which resulted in a $500 Special Performance Cash Award. On other tours I worked on natural language processing tools, telecommunications, and hardware design of an encryption chip.
__________________________________________________
And then, 9/11/2001 happens and the whole damn Internet is data mined by the NSA...
"Don't be evil."
(This brilliant philosophy is approved by noted scholar Barry Kort.)
(This brilliant philosophy is approved by noted scholar Barry Kort.)
QUOTE(GlassBeadGame @ Tue 27th January 2009, 11:42am)
By the way, Jon, can you break down the architecture stuff a little. I couldn't really follow it.
Brin and Page's paragraph on Intuitive Justification is probably the best by way of a Schort Begriffsschrift:
QUOTE
2.1.2. Intuitive Justification
PageRank can be thought of as a model of user behavior. We assume there is a "random surfer" who is given a web page at random and keeps clicking on links, never hitting "back" but eventually gets bored and starts on another random page. The probability that the random surfer visits a page is its PageRank. And, the d damping factor is the probability at each page the "random surfer" will get bored and request another random page. One important variation is to only add the damping factor d to a single page, or a group of pages. This allows for personalization and can make it nearly impossible to deliberately mislead the system in order to get a higher ranking. We have several other extensions to PageRank, again see [Page 98].
Another intuitive justification is that a page can have a high PageRank if there are many pages that point to it, or if there are some pages that point to it and have a high PageRank. Intuitively, pages that are well cited from many places around the web are worth looking at. Also, pages that have perhaps only one citation from something like the Yahoo! homepage are also generally worth looking at. If a page was not high quality, or was a broken link, it is quite likely that Yahoo's homepage would not link to it. PageRank handles both these cases and everything in between by recursively propagating weights through the link structure of the web.
Source. «What's in the Brin that Links May Character?»
Ja³
QUOTE(bambi @ Tue 27th January 2009, 9:21am)
And then, 9/11/2001 happens and the whole damn Internet is data mined by the NSA...
Don't kid yourself. The NSA was examining email and Usenet long before 9/11,
Intelligence Directive 18 be damned. It was just done on an "informal" basis.
Read up on the NARUS STA 6400 sometime. It was developed in the late 90s.
Also remember In-Q-Tel.
And Verint.
It didn't REALLY get serious until Dubya got to the White House. The Patriot Act
was the perfect excuse to kill off USSID 18 and troll thru all net traffic. The
technology was already developed and ready.
This is a "lo-fi" version of our main content. To view the full version with more information, formatting and images, please click here.